靳瑞哲,迟 楠
(1.复旦大学 通信科学与工程系,电磁波信息科学教育部重点实验室,上海 200433;
2.鹏城实验室,广东 深圳 518055)
随着物联网、云计算、增强现实(Augmented Reality,AR)、虚拟现实(Virtual Reality,VR)和数字孪生等一系列新技术的蓬勃发展,通信网络传输容量和覆盖范围将出现爆发式增长。我国《“十四五”国家信息化规划》中提出,在2025年前要实现数字中国建设决定性进展,信息化建设水平大幅提升。无线和光通信网络作为信息建设中的重要建设设施,是实现该目标的坚实基础和有利支撑。为满足未来通信网络提出的“空天地海”要求,克服不同传输信道损伤和达到不同传输性能要求,必须在通信网络中应用不同的信号调制格式。面对高度混合的通信网络,对于接收端,如何在缺乏先验知识时对信号进行解调等一系列数字信号处理至关重要。通过应用调制格式识别技术,可以准确分类得知信号调制格式,例如正交振幅调制(Quadrature Amplitude Modulation,QAM)信号,为后续一系列非线性补偿和频率偏移补偿等打下基础。
调制格式识别主要分为两大技术分支:基于似然比和基于特征提取的调制格式识别技术。基于似然比的调制格式识别技术的研究主要集中于上世纪,通过构造似然函数,利用不同调制格式信号似然函数值不同的特点完成对信号调制格式的识别。虽然基于似然比的调制格式有贝叶斯意义上的最优解,但这类系统的计算复杂性通常很高,通常需要缓冲大量样本进行计算,且在未知信道条件或时钟频率偏移等情形下也不可靠,因此逐渐淡出研究焦点。基于特征提取的调制格式识别技术主要分为两步:首先对信号进行特征提取,随后根据所提取的特征,设计合适的分类器以达到最好的分类效果。从信号提取特征这一角度,基于似然函数的调制格式识别技术为基于特征提取的调制识别技术打下了基础,即早些年构造似然函数中所使用的一些特征量,如:高阶累积量[1]和频谱特征[2]等可以被特征提取所用,在这一点上两者是共通的。对于特征量的选择,在几十年的研究中较为成熟;
而如何根据目标特征量设计合适的分类器以更快、更准确地完成分类识别成为调制格式识别领域当下的研究热点。
对于分类器的选择,当下研究热点主要聚焦于将机器学习方法应用于分类器的设计中。传统的机器学习方法包括:支撑向量机(Support Vector Machine, SVM)、聚类算法和神经网络等。近些年,随着深度学习神经网络的蓬勃发展,得益于深度学习在特征提取和分类聚类能力上相较于传统方法的显著优势,将深度学习应用于调制格式识别技术中具有非常广阔的潜力。
1.1 基于机器学习的特征提取调制格式识别模型
基于机器学习的特征提取调制格式识别模型如图1所示。识别模型主要分为两个部分,首先利用训练模型建立分类器模型,随后在识别模型中利用所建立的分类器实现对信号调制格式的识别。

图1 基于机器学习的特征提取调制格式识别模型Figure 1 Modulation format recognition model based on feature extraction and machine learning
在训练模型中,首先需要构造一系列已知调制格式的信号,即训练信号。在对训练信号进行加噪等一系列操作以模拟实际信道对信号的损伤效果后,对信号进行特征量的提取,随后对提取的特征进行训练,最终得到所需的分类器模型。在识别模型中,接收端从网络中接收到识别信号,经过特征提取后,依照分类器模型完成对信号的分类识别。
1.2 特征提取调制格式识别中的机器学习算法
机器学习算法主要分为传统机器学习算法和深度学习神经网络。传统的非深度学习机器学习算法如决策树、SVM和聚类算法(如K-means)等,这些算法需要研究人员依靠先验知识,对算法的模型结构和一些重要参数进行手动设计,较为繁琐,但优势在于所需的计算资源较少;
深度学习神经网络则利用多层神经网络结构解放了繁琐的手动设计过程,在调试好神经网络后,即可利用神经网络算法自动完成特征挖掘和分类提取的功能,但通常需要消耗大量计算资源和计算时间。不同算法由于其算法的特点不同,所适用的特征量也有所不同。例如对于采用聚类算法的方案,常常使用星座图这样需要完成聚簇操作的特征量;
采用卷积神经网络(Convolutional Neural Network,CNN),其所输入的特征量几乎均为二维特征量,如眼图、星座图和循环谱图等;
采用循环神经网络(Recurrent Neural Network, RNN),所输入的特征量主要为信号的瞬时量,如时间与幅度值等。图2所示为基于机器学习的调制格式识别方法分类图。
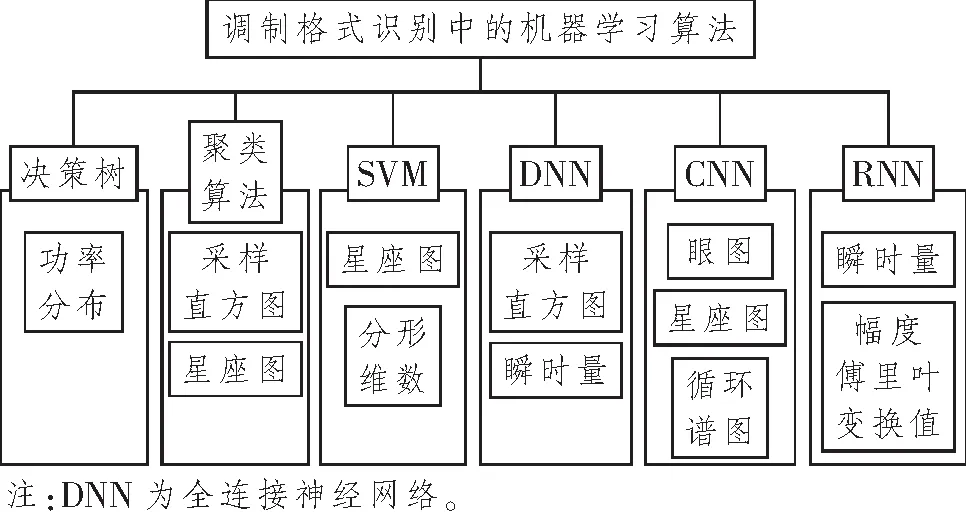
图2 基于机器学习的调制格式识别方法分类Figure 2 Classification of modulation format recognition methods based on machine learning
2.1 基于决策树的调制格式识别方法
使用决策树进行调制格式识别需要研究人员根据信息和信道的先验信息与专业知识对信号所有可能的调制格式进行判决条件的设计。2014年,香港理工大学的Liu等人提出了一种基于信号功率分布的调制格式识别技术[3]。文章分析了不同调制格式在功率归一化的情形下,由于星座点分布的不同,整体信号的功率概率分布不同,从而完成对信号调制格式的区分。文章提出的决策树如图3所示,通过设计合适的信号概率比率阈值进行信号调制格式的识别,图中R1、R2、R3和R4均为信号功率分布比率,计算式分别为
式中,P为比率;
S为信号功率。

图3 基于决策树的调制格式识别流程[3]Figure 3 Modulation format recognition process based on decision tree
将决策树分类器与不同的信号特征结合能够获得新的调制格式识别方案。如2020年,北京理工大学的Zhao等人提出了将信号幅度排序和比值计算与决策树结合的调制格式识别方案[4],接收端接收信号之后,对信号序列中符号振幅进行排序,根据振幅大小分成不同集合,随后根据不同信号格式对应的集合各分布比例完成决策树设计;
同年,聊城大学的Yu等人将密度直方分布图的特征与决策树结合[5],将接收到的信号序列处理为密度直方图,由于不同的信号调制格式所对应的局部极值点数量不同从而完成决策树设计。
通过决策树对信号的功率分布进行判断从而实现信号识别的方案对信号的信噪比(Signal Noise Ratio,SNR)要求较高,当SNR条件较差时,会由于噪音的分布影响信号的实际特征分布使得判断错误。使用决策树作为分类器具有易于解释、速度快和占用内存少等优点,但其估计精度较低,面对复杂情况时手动设计决策树十分繁琐,且由于设计决策树方案时依托了大量先验信号和信道先验信息,在信号特征发生改变或信道特征发生改变时,决策树方案可能需要重新设计,因此可移植性较低。
2.2 基于聚类算法的调制格式识别方法
聚类算法有许多不同的算法分支,最具有代表性的为K-means算法。K-means算法为一种无监督的聚类算法,在设置了质心点数后(即K值),即可根据算法进行聚类操作。K-means的算法流程如图4所示,在设置完质心数,随机初始化质心位置后,根据算法不断调整质心位置,按照样本与质心距离大小,将样本划分为K个簇,使每个簇内部的点尽量紧密,多次迭代后完成聚类操作。2010年,丹麦科技大学的Gonzales等人提出了基于K-means算法的特征识别技术[6]。文章首先生成了不同调制格式的信号,随后利用K-means算法对不同格式的星座图进行识别判断,借助幅度直方图的信息,通过遍历知识数据库中所有可能的格式进行一一比对,直到成功识别为止。与K-means算法类似的聚类算法还有基于密度的噪声应用空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法,相较于K-means算法需要人为设置质心点数,DBSCAN算法可以自行进行分类聚类,但由于缺少了人为设置质心点数这一步,其分类数常常有些许偏差。例如2020年,北京理工大学Zhao等人提出使用DBSCAN算法处理信号星座图以进行调制格式识别[7]。与K-means算法相似,不同调制格式信号经DBSCAN算法完成聚类后的质心点数不同,但由于缺少K值信息,质心数呈现范围分布,因此分类精度有所降低,但信号处理流程更加简便。

图4 基于K-means算法的调制格式识别示意图Figure 4 Modulation format recognition schematic diagram based on K-means
使用聚类算法进行分类具有算法解释性强、收敛速度快且消耗计算资源较少的优点,但在复杂的信道情形,聚类算法由于其对噪点非常敏感,因此在SNR较低的情形下效果较差,且识别结果在实际分类时不好确定判决阈值,因此常常需要使用大量实际测得的数据完成数据库的建立,才能将实际测得的结果与数据库数据匹配从而得到识别结果。
2.3 基于SVM的调制格式识别方法
SVM的算法流程如图5所示,根据数据可分为两种情形:线性可分和线性不可分。对于线性可分,利用算法寻找支撑向量,使得支撑向量两侧的点与支撑向量间的几何间距最大。其中,使用公式wTx+b=0表征支撑向量表达式,wT为支撑向量法向量,b为偏移量。在实际应用中,主要以线性不可分情形为主。由于不能直接找到支撑向量,因此利用核函数将样本空间升维,在更高的维度下可以找到一层超平面使样本数据分别分布在两侧,随后将超平面降维到原数据空间,从而得到一条分割曲线。2010年,西南交通大学的Huang等人提出了基于SVM的特征识别技术[8],文章利用推导出的分形维数公式,对信号进行预处理后得到信号的分形维数值与方差值,随后以分形维数值和方差值构造二维坐标系,通过SVM完成这一坐标系中数据点的分类,从而实现信号调制格式的识别;
2022年,北京邮电大学的Jiang等人提出将信号去噪后的星座图作为SVM的特征,实现了7种调制格式的分类[9],文章首先对信号进行预处理,通过平方运算和主成份分析消除了星座图相位旋转的影响,并对星座密度矩阵进行奇异值分解,实现星座去噪,提高星座质量,最终将预处理完成的星座图数据利用多次SVM完成对星座点的切割分类,依据最终分割出的星座点簇数完成调制格式识别。

图5 基于SVM的调制格式识别示意图Figure 5 Modulation format recognition schematic diagram based on SVM
SVM的可解释性强,分类效果好。但由于需要进行样本点的升维和间隔计算等一些操作,因此对于大量样本点难以实施,且SVM本质上是一个二值分类器,这意味着对于多个调制格式需要大量SVM构成一个系统后才能满足需求,较为繁琐。
2.4 基于DNN的调制格式识别方法
DNN通过增加隐藏层的层数,可以直接提升可提取特征的维度。特征提取能力的增强和分类能力的增强带来的代价即为运算复杂度的提升,所需要的算力资源也相应增加。与其他领域应用DNN的经验相同,DNN层数的增加对识别正确率的提升并不是正相关,而是存在一个最佳值。这是由于,层数较少的情形下,由于提取特征维度较低导致出现欠拟合;
而层数过多则会出现过拟合的现象。因此,根据实际情形设计合适的层数和神经元个数等超参数是设计一个好的DNN的核心。
2017年,香港理工大学Khan等人提出将DNN与信号幅度直方图相结合以实现调制格式识别[10],文章提出的DNN结构如图6所示,Xi为输入数据,xi、ui和vi为神经元。该DNN共有两层隐藏层,第1层隐藏层有30个神经元,第2层隐藏层有10个神经元,随后通过输出层,按照输出层的编码确定调制格式,在接收端接收到信号后,首先对信号进行预处理,将信号序列转化为直方图数据,随后将直方图数据作为输入数据输入进DNN进行训练和识别;
与之类似的,2020年,韩国高级科学技术研究院的Kim等人提出将信号的幅值方差与SNR作为特征量输入进DNN中进行调制格式识别[11];
2020年,上海交通大学的Huang等人提出了将异步幅度直方图与DNN结合的方法[12],能在带宽限制为30%~40%的情况下实现高于95%的调制格式识别准确率。
通过使用DNN进行调制格式识别,能将研究人员从繁琐的方案设计中解放出来,通过多层网络结构充分挖掘信号数据特征。但DNN需要大量计算资源和处理时间,因此合理设计超参数,即隐藏层层数和神经元个数,对计算时间、计算资源和识别准确率有非常关键的影响。

图6 基于DNN的调制格式识别示意图Figure 6 Modulation format recognition schematic diagram based on DNN
2.5 基于CNN的调制格式识别方法
CNN最先在图片识别领域开始大规模使用,由于其独特的卷积层和池化层结构,相较于DNN可以在大幅减小网络复杂度的同时有效提取局部特征。这一优点也受到了调制格式识别技术领域的青睐。研究者开始尝试将之前常用的二维信息,如星座图和频谱图等,作为数据集放入CNN中进行训练,由于网络结构相较DNN简单,可以用更大规模的数据集进行训练。但由于数据集规模的增大,不可避免地会使训练时长相比于DNN更长,运算复杂度更高。设计CNN时,与DNN相同,需要依据使用场景,根据研究者自身经验设计合理的超参数。图7所示为CNN用于调制格式识别的流程与结构,参数Ai为神经元。在接收端接收到信号后,经过预处理将信号处理为二维信息,例如星座图、眼图和时频谱图等,随后将二维信息输入CNN中进行训练和识别。经过展平层、全连接层和SoftMax层之后,得到每个可能的调制格式的概率,从中选择最大概率的结果作为识别结果。

图7 基于CNN的调制格式识别示意图Figure 7 Modulation format recognition schematic diagram based on CNN
2017年,北京邮电大学的Wang等人提出选择眼图作为处理目标[13]。利用示波器和仿真系统生成4种调制格式,SNR范围为10~25 dB。文章将接收端接收到的眼图经过下采样得到像素点较少的灰度眼图以减小数据规模。网络结构由两层卷积层和两层池化层组成卷积部分,随后将输出平坦为一维信号,输入到全连接层,最后得到识别结果。文章为了对比CNN的效果,将CNN的识别效果和传统的4种算法进行对比:决策树、K最邻近法(K-Nearest Neighbor,KNN)、人工神经网络和SVM,最后得到结论,CNN由于其能有效地提取高维信息,识别效果远远优于传统的非深度学习机器学习算法。
为了进一步探究CNN在调制格式识别这一领域的潜力,研究者尝试了各种其他的二维数据集,以期获得不一样的性能。常见的二维图像有模糊函数图像[14]、谱相关函数图像[15]和离散傅里叶图像[16]等。2019年,南方科技大学的Zeng等人提出[16],不同调制格式的无线电信号之间最重要的区别即为频率随时间的变化,文章据此提出,利用短时离散傅里叶变换,将一维无线电信号转换为频谱图图像,以频谱图图像作为数据集输入到CNN中进行训练。与前文提到的将眼图作为输入图像类似,频谱图通过仿真系统得到后,也经过下采样以减小数据集的规模。类似地,2020年,北京邮电大学的Du等人将异步幅度直方图作为特征量输入到CNN中进行训练[17];
2021年,北京科技大学的Lü等人尝试直接利用信号幅度直方图与CNN结合以获得较低的复杂度和识别性能[18]。
CNN相较于DNN,得益于卷积层和池化层的独特设计,能很好地解决参数膨胀的问题;
且由于卷积核的设计,能很好地提取局部特征,这大大地提高了网络效率。但与DNN的问题相同,即需要精心设计卷积层和池化层的层数、卷积核的个数与尺寸等超参数,以达到最好性能。
2.6 基于RNN的调制格式识别方法
RNN最先在语音识别领域开始使用,具有神经结构与时间有关联的特点。针对CNN的一些不足,例如对于采样率未知的数据,或者在训练CNN模型阶段中从未遇到过的脉冲成形滤波器等数据,CNN的识别能力可能会下降;
CNN作为一个固定输入长度的模型,其可处理的调制符号的数量在不同的符号速率中是有限的。因此,为了满足对可变样本率和序列长度能进行有效处理这一需求,研究者认为RNN作为一个可变输入长度模型,可以很好地满足上述要求。为了处理RNN常见的梯度爆炸问题,其有很多变形,例如长短时记忆(Long Short-term Memory,LSTM)神经网络和门控循环单元(Gated Recurrent Unit,GRU)网络等变体,均为调制格式识别领域的热点。RNN虽然不能如CNN这样通过卷积操作进行局部特征提取,但由于其可以满足可变长度数据集的输入,而引起了研究者的兴趣。
2018年,比利时鲁汶大学的Rajendran等人提出了一种基于LSTM的方案[19],可以通过学习长期时间序列,在不进行显式特征提取的情形下实现分类。该实验使用的LSTM网络如图8所示,其中LSTM网络将训练信息分为两类,分别为长期信息ct与短期信息ht,Xt为输入,σ为激活函数,常用sigmoid函数,yk代表输入层神经元。文章使用了两层LSTM模型,使用幅度—相位信号或平均幅度快速傅里叶变换(Fast Fourier Transform,FFT)信号作为输入数据集,在经过输入层和两层LSTM层后,经过全连接层和SoftMax层得到判别结果。值得指出的是,当以时域同相信号和正交信号样本作为输入时,识别效果较差,而以时域振幅和相位信息作为输入时,准确率能达到90%,说明虽然DNN擅长函数逼近,但数据集的预处理和数据的正确表示对识别结果同样非常重要。为了充分利用神经网络各结构的特点,研究者们尝试在网络结构上进行进一步的创新。2020年,北京理工大学的Chen等人构造了双向RNN (Bi-directional Recurrent Neural Network,BRNN)来获取时间特征[20],并进一步与循环连接CNN结合来提取接收信号的空间特征,通过充分提取信号特征完成调制格式识别;
与之相似的,2021年,韩国库莫国立理工学院的Njoku等人将GRU网络结构与CNN和DNN结构相结合形成混合神经网络[21],通过互补的方式完成取长补短,将信号的同相分量和正交分量作为输入信号特征,实现了很好的识别性能;
2022年,北京邮电大学的Chang等人将Bi GRU网络结构与CNN和DNN结合[22],文章对比了输入信号特征分别为I/Q分量与振幅相位信息两种情况并指出两者分别在高和低SNR下有更佳的识别性能。
RNN得益于特殊的神经元设计,赋予了网络对当前数据前面的数据序列“记忆”的功能,能更好地提取信号序列数据之间的特征。但RNN所需的计算资源和计算时间非常大,不利于实时系统的设计;
且由于RNN本身神经元结构的多变,能否根据信号特点设计合适的神经元结构以及RNN各个隐藏层层数等超参数常常非常影响识别性能。
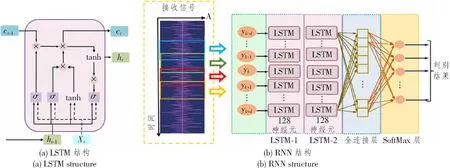
图8 基于RNN的调制格式识别示意图Figure 8 Modulation format recognition schematic diagram based on RNN
基于特征提取的调制格式识别技术通过合理设计分类器,在分类器设计完成后,即可在不受人监督和操作下实现调制格式的识别。机器学习因其优异的分类和聚类能力被广泛应用于分类器的设计中。机器学习以深度学习的出现为界限,传统机器学习方法如决策树等需要根据先验知识实际设计分类方案,较为繁琐且不具有可移植性;
DNN通过多层网络的设计,将研究人员从繁琐的分类器设计中解放出来。此外,深度学习允许增量学习,无需从头开始训练整个网络,可以更快速地获得新的信号特征,从而具有非常高的移植性和自主性。值得指出的是,经过几年对深度学习在模式识别领域的研究后,当下各类神经网络结构均已被研究者运用在了模式识别领域;
虽然每一种网络都有各自的特点,但都面临着存在某一指标较差导致较为限制实际应用的问题,如CNN不能应对采样率改变的信号,RNN计算量大训练时间长等等。
未来的通信网络将更加灵活,包括更加多样的调制格式,如何使用更少的计算资源和更少的计算时间达到更高的识别准确率为调制格式识别领域持之以恒的目标。这要求未来的识别算法使用更加适合恰当的结构,以提取包含信号更多特点的信号特征,并更加精准地对信号特征进行分类。
猜你喜欢 决策树特征提取分类器 一种针对不均衡数据集的SVM决策树算法成都信息工程大学学报(2019年3期)2019-09-25基于Gazebo仿真环境的ORB特征提取与比对的研究电子制作(2019年15期)2019-08-27基于Daubechies(dbN)的飞行器音频特征提取电子制作(2018年19期)2018-11-14决策树和随机森林方法在管理决策中的应用电子制作(2018年16期)2018-09-26基于差异性测度的遥感自适应分类器选择电子技术与软件工程(2017年14期)2017-09-08基于实例的强分类器快速集成方法计算机应用(2017年4期)2017-06-27Bagging RCSP脑电特征提取算法自动化学报(2017年11期)2017-04-04基于决策树的出租车乘客出行目的识别中央民族大学学报(自然科学版)(2016年4期)2016-06-27基于肺癌CT的决策树模型在肺癌诊断中的应用郑州大学学报(医学版)(2015年1期)2015-02-27基于MED和循环域解调的多故障特征提取噪声与振动控制(2015年4期)2015-01-01